Implementing the Power of Data: Revolutioninzing Biochemistry with the Magic of Data Science (Part I)
Introduction:
Biochemistry, a field that sits at the crossroads of biology and chemistry, holds the key to unlocking the mysteries of life processes and to revolutionizing the development of pharmaceuticals. It is a discipline driven by the relentless quest to understand the intricacies of biomolecules, pathways, and cellular processes that underlie health and disease. In recent years, a formidable ally in data science has joined the ranks of biochemists and researchers. This partnership is shaping the future of life sciences and pharmaceutical research in profound ways.
The marriage of biochemistry and data science marks a pivotal moment in scientific progress. Traditional laboratory techniques, though invaluable, often fall short in the face of the vast amounts of data generated by cutting-edge experimental methods such as genomics, proteomics, and structural biology. Data science, a multidisciplinary field that harnesses the power of statistical analysis, computational modeling, and machine learning, has emerged as an indispensable tool to navigate this sea of information. It not only helps manage and interpret vast datasets but also empowers scientists to gain meaningful insights and make critical breakthroughs.
As we continue to understand the transformative role of data science in biochemistry, our journey leads us into the realm of protein modeling, a domain where data science's precision and predictive power offer new horizons for understanding the fundamental building blocks of life. We'll also delve into how data science is revolutionizing the pharmaceutical industry, accelerating the drug discovery process and addressing some of the most pressing healthcare challenges. Together, these aspects showcase the incredible impact of data science in reshaping the future of biochemistry and the life sciences.
Protein Modelling:
Proteins are the workhorses of life, carrying out essential functions within the cells of all living organisms. Understanding their structures and functions is at the core of biochemistry, as it allows us to comprehend the intricate mechanisms of life processes. Protein modeling, a process that simulates and predicts protein structures, is a critical facet of the field. While traditional methods, such as X-ray crystallography, Electron Microscopy, and Nuclear Magnetic Resonance (NMR) spectroscopy, have been instrumental in determining protein structures, they can be time-consuming, costly, and challenging. More importantly though, these methods are often limited by the protein's physical characteristics, like flexibility, size and ability to crystallize of the protein.
This is where data science steps in as a game-changer in protein modeling. Data scientists leverage machine learning algorithms to refine and improve protein models by utilizing vast amounts of structural protein data that has been collected; these algorithms can process known protein structures, amino acid sequences, and experimental data, to create accurate predictions of protein structures. The power of data science lies in its ability to infer the three-dimensional arrangement of atoms in a protein by learning from the vast catalog of protein structures available.
By harnessing the capabilities of data science, researchers can overcome the limitations of traditional protein modeling methods. They can model protein structures more rapidly and accurately. With data science, prediction of such structures can be made with great accuracy as physical limitations of the protein structure will not be relevant (besides a lack of past research, perhaps). The program “AlphaFold” is a remarkable example of how data science is revolutionizing protein modeling. Developed by DeepMind, AlphaFold employs advanced machine learning and deep learning algorithms to predict protein structures with astonishing accuracy. By harnessing vast amounts of biological data, including 170,000 protein sequences and known structures, AlphaFold trains itself to decipher the complex folding patterns and 3D structures of proteins, even for those with elusive or previously unknown configurations, with just the primary protein sequence. Its precision and speed in protein modeling are game-changing, promising significant advancements in our understanding of biological systems and the potential for groundbreaking drug discovery and personalized medicine. Alpha Fold has over 200 million protein structure entries, including protein complexes! One major limitation, however, is lower confidence in the model when it comes to co-factor analysis, and limitation to only one protein conformation even for protein with several conformations [1].
It is become increasingly clear that the application of data science to protein modeling has the potential to revolutionize how we approach healthcare and improve our understanding of the fundamental building blocks of life. Further yet, the use of software like Alpha Fold are rapidly improving to exceed their limitations.
Data-Driven Drug Discovery:
The process of drug discovery has historically been a time-consuming, expensive, and often inefficient endeavor, involving a trial-and-error approach that requires extensive resources. Once again, data science has ushered in a new era of drug development, where the focus is on data-driven approaches that accelerate the identification, optimization, and design of potential drug candidates.
Data science has been essential for analyzing patient data for drug tests and developing studies, but the most significant contribution in drug discovery is the research of potential drug candidates. Through analyzing of vast datasets, including genomic and proteomic data, chemical compound libraries, and clinical trial information, data scientists can pinpoint molecules that exhibit the desired therapeutic effects, as well as any malignant effects. By understanding the genetic underpinnings of diseases and the interactions between proteins and small molecules, researchers can target specific biological pathways, significantly improving the efficiency of candidate selection.
Optimizing drug design and predicting drug interactions and potential side effects is another area where data science plays a transformative role. Computational models powered by data science can predict the interactions between drug candidates and target proteins with high precision. This reduces the need for costly and time-consuming laboratory experiments, enabling researchers to fine-tune drug compounds for enhanced efficacy and reduced side effects instead of relying solely on a hit-and-try method. Additionally, data-driven drug design allows for the exploration of large chemical libraries to discover novel compounds with therapeutic potential. This not only saves time and resources but also enhances patient safety by reducing the likelihood of unexpected adverse effects during clinical trials.
Furthermore, the community believes that one day data-driven drug discovery will enable the development of personalized medicine. By considering an individual's genetic makeup and the unique molecular profile of their disease, researchers can design treatments tailored to a patient's specific needs. This approach holds the promise of more effective therapies with fewer side effects, but also require collection, processing and analysis of data on a much larger scale, the requirements for which can be met by constantly advancing data science driven software and applications.
Several data-driven software and applicationshave been created that researchers can utilize to conduct protein-docking simulations to study drug discovery themselves, including PyMol, HADDOCK, Schrodinger and more. I have personally made us of AutoDock Vina, which is a highly valuable protein-ligand docking simulator widely employed in computational drug discovery and molecular biology. By simulating the molecular recognition and binding process, AutoDock helps researchers understand how ligands interact with target proteins, enabling the identification of novel drug compounds and the optimization of existing ones. Its versatility and accuracy make it an essential tool for virtual screening, lead optimization, and structure-based drug design, significantly expediting the drug development process and contributing to the discovery of new therapies. AutoDock is one of the most widely cited docking software globally, and has been used for OpenPandemics Projects to find antivirals for AIDS and Covid-19. AutoDock was utilized in the development of HIV-1 integrase inhibitor developed by Merck and Co [2].
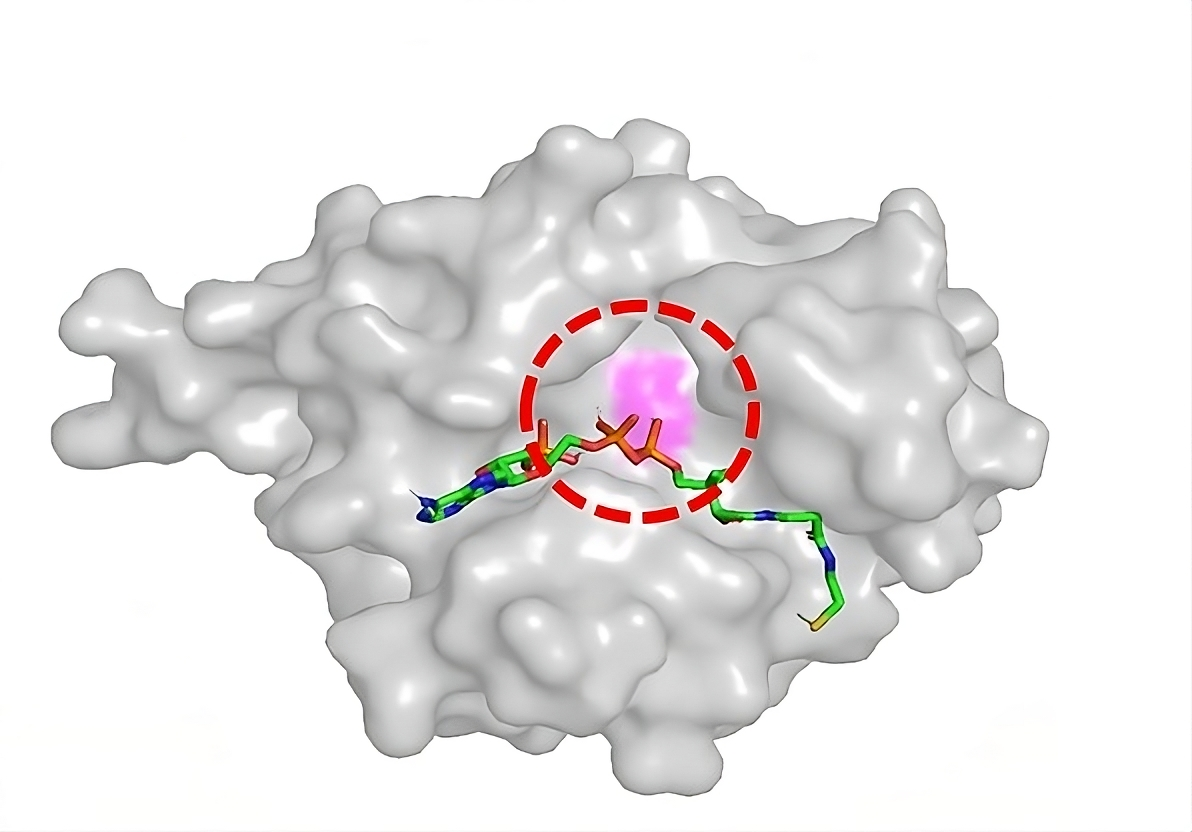
Shown here is a docking model I generated using AutoDock Vina and PyMol. While working in a research group at UCL, I was pursuing a project to understand the interaction of Coenzyme A (shown in the colorful, stick form) with the enzyme S. aureus Nucleoside Dependent Kinase (shown in the gray, surface form). With knowledge of the structures and their potential interaction, I was able to generate a theoretical model of their docking mehcanism, including the exact point where the interaction would occur, giving me further context on the type and strength of interaction between the two species.
To understand how the utilization of Data Science in Biochemistry even further with Big Data and Bioinformatics, and delve into a discussion of the ethical considerations that come into play when Data Science and Biochemistry and combined, please continue to Part II of the article.
References:
[1] Yang, Z., Zeng, X., Zhao, Y., & Chen, R. (2023). AlphaFold2 and its applications in the fields of biology and medicine. Signal Transduction and Targeted Therapy, 8(1), 115.
[2] Forli, S., Huey, R., Pique, M. E., Sanner, M. F., Goodsell, D. S., & Olson, A. J. (2016). Computational protein-ligand docking and virtual drug screening with the AutoDock suite. Nature protocols, 11(5), 905-919.